你如星辰入海,倾万鲸成宇宙。
尚东峰-<鱼辞>
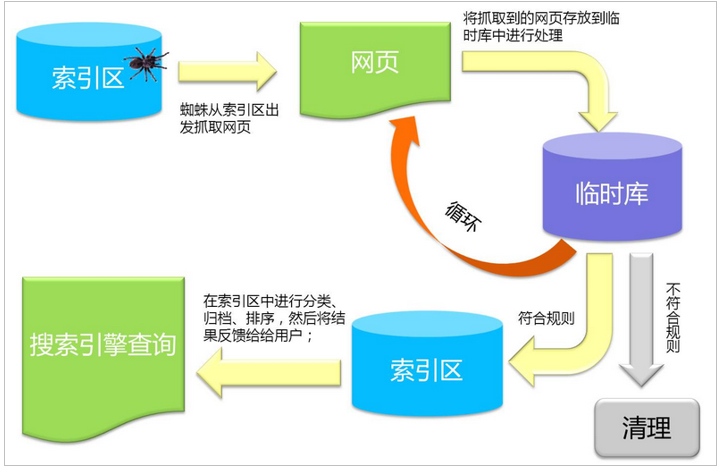
一.搜索引擎原理.
二.什么是lucene
1 | Lucene是一套用于全文检索和搜寻的开源程序库,由Apache软件基金会支持和提供. |
1.什么是全文检索.如何实现.
计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式.通过分词.
对要搜索的内容先创建索引,然后再通过索引进行搜索的过程.
倒排索引: 又叫反向索引,以字或词为关键字进行索引,表中关键字所对应的记录表项,记录了出现这个字或词的所有文档,每一个表项记录该文档的ID和关键字在该文档中出现的位置情况.
总结:对文档(数据)中每一个词都做索引.
2.索引和搜索的流程
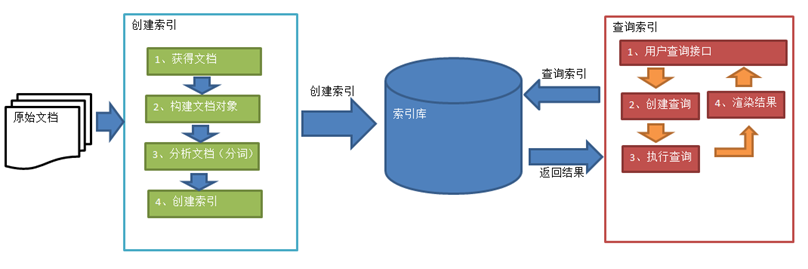
1 | 1、绿色表示索引过程,对要搜索的原始内容进行索引构建一个索引库,索引过程包括: |
二.Lucene的基本使用
使用Lucene的API来实现对索引的增(创建索引)、删(删除索引)、改(修改索引)、查(搜索数据)
1.新建一个普通的maven项目.
2.导入pom相关依赖.
1 | //(出现红叉记得maven/update project) |
3.创建索引库
1 | public class Lucene { |
运行创建索引库成功:
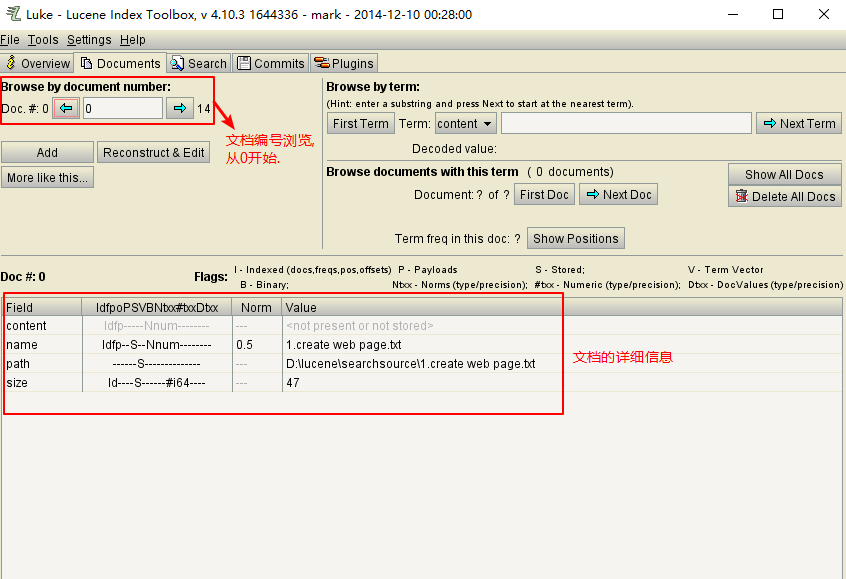
4.使用luke工具查看索引文件
运行start.bat打开.
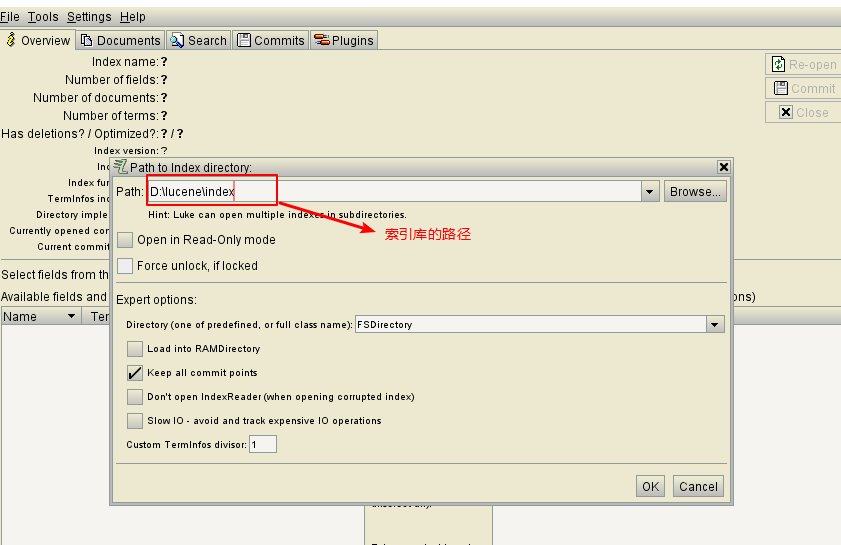
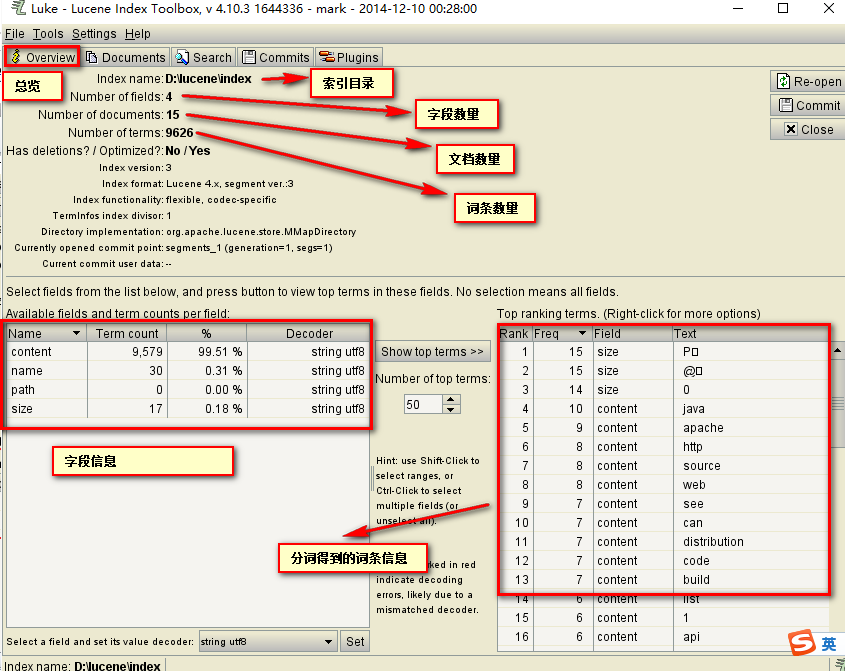
文档列表:
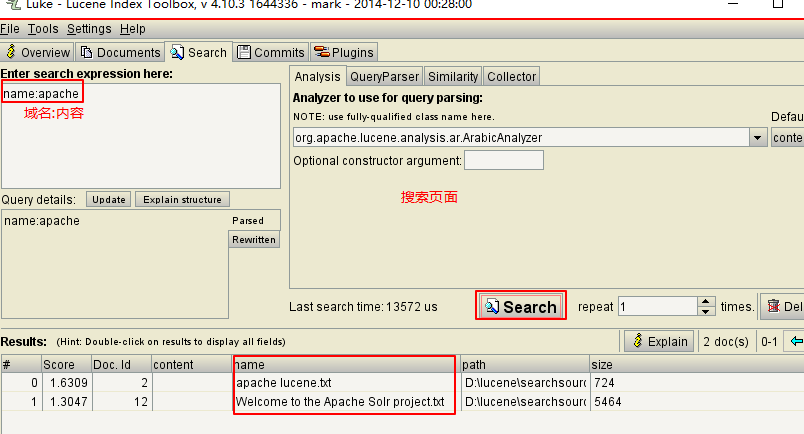
搜索页面:
5.查询索引器
1 | //查询索引库 |
6.IK中文分词器
优点: 中文分词更专业,可以扩展自定义词库(扩展词典和停用词典).
1 | <!-- 引入IK分词器 --> |
1 | //查看IK分析器的分词效果 |
7.添加文档
1 | //添加文档 |
8.删除文档
1 | public IndexWriter getIndexWriter() throws Exception { |
9.更新索引库
1 | //更新索引库(本质:先删除后添加) |
10.Query子类查询-查询所有文档
1 | //查询所有文档 |
1 | //提取重复代码 |
11.数值范围查询
1 |
|
12.组合条件查询
1 | //Occur.MUST:必须满足此条件,相当于and |
13.使用Queryparse查询
通过QueryParser也可以创建Query,QueryParser提供一个Parse方法,此方法可以直接根据查询语法来查询。Query对象执行的查询语法可通过System.out.println(query);查询。需要使用到分析器。建议创建索引时使用的分析器和查询索引时使用的分析器要一致。
1 |
|
14.Lucene查询语法
1 | 1、基础的查询语法,关键词查询: |
15.指定多个默认搜索域
1 |
|